
Daily Leads and Partners
date_id 및 make_name마다 고유한 lead_id 및 partner_id의 개수를 구하시오.

python
print(DailySales.groupby(['date_id', 'make_name']).nunique().reset_index())
- group by로 id, 이름별로 그룹핑 후, nunique()으로 고유한 행의 개수 출력
SQL
select date(date_id) as date_id, make_name, count(distinct lead_id) as unique_leads, count(distinct partner_id) as unique_partners
from DailySales
group by date_id, make_name
- distinct와 count로 고유한 행의 개수를 출력
Actors and Directors Who Cooperated At Least Three Times
다음 테이블에서 3번 이상 협력한 배우와 감독의 id를 출력하시오.
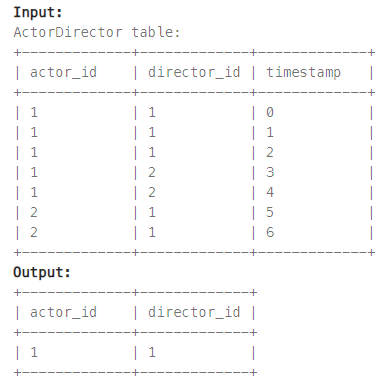
python
result = ActorDirector.groupby(['actor_id','director_id']).count().reset_index()
print(result[result['timestamp'] >= 3][['actor_id','director_id']])
SQL
select actor_id, director_id
from ActorDirector
group by actor_id, director_id
having count(*) >= 3
- having 절로 그룹에 조건을 줘서, 행이 3개 이상인 경우만 출력
Replace Employee ID With The Unique Identifier
다음 2개의 테이블에서 각 사용자의 고유 ID를 출력하시오. (단, 사용자에게 고유 ID가 없으면 NULL을 표시)

python
pd.merge(Employees, EmployeeUNI, on = 'id', how = 'left')[['unique_id', 'name']]
- pd.merge() : SQL의 join을 pandas에서 사용할 수 있는 함수
- on : 공통된 조건 column 지정, 테이블의 column 이름이 서로 다른 경우 left_on, right_on 사용
- how : join 방식 지정, default는 inner join이며 left, right를 지정할 수 있음
- 여기서는 왼쪽 테이블에 NULL이 있어야 하기 때문에 left join 사용
SQL
select u.unique_id, e.name
from Employees E
left join
EmployeeUNI u
on u.id = e.id
- python과 동일한 방식으로 join 진행
- join : join은 DB에서 두 개 이상의 테이블을 결합하여 하나의 결과 테이블로 만드는 연산으로, DB에서 정보를 조합하고 연관시키기 위해 사용된다. join의 종류는 다음과 같다.
- inner join : 테이블에서 일치하는 레코드만 반환한다. 공통된 값을 기반으로 결과를 생성하기 때문에, 일치하지 않는 행은 포함하지 않는다.
- left join(left outer join) : left join은 왼쪽 테이블의 모든 레코드와 오른쪽 테이블에서 일치하는 레코드를 가져온다. 오른쪽 테이블에 일치하는 레코드가 없으면, 왼쪽 테이블의 결과는 NULL로 채워진다.
- right join(right outer join) : right join은 left join과 반대로 오른쪽 테이블의 모든 레코드와 왼쪽 테이블에서 일치하는 레코드를 가져온다. 왼쪽 테이블에 일치하는 레코드가 없으면, 오른쪽 테이블의 결과는 NULL로 채워진다.
- full join(full outer join) : 왼쪽 테이블과 오른쪽 테이블의 모든 레코드를 가져온다. 양쪽 테이블에서 일치하는 레코드와 일치하지 않는 레코드를 모두 포함시키고, 일치하지 않는 경우는 위와 동일하게 NULL 값이 채워진다.
- cross join(cartesian product) : 두 테이블의 모든 행을 결합하여 가능한 모든 조합을 만든다. 두 테이블 간에 어떠한 조인 조건도 사용하지 않으며, 결과로 생성되는 행 수는 첫 번째 테이블의 행의 수와 두 번째 테이블의 행의 수를 곱한 값과 동일하다. 하지만, 큰 테이블을 사용하거나 복잡한 쿼리를 실행하면 시간이 오래걸릴 수 있기 때문에 대부분의 경우 조인 조건을 활용하는 것이 더 효율적이다.
- inner join : 테이블에서 일치하는 레코드만 반환한다. 공통된 값을 기반으로 결과를 생성하기 때문에, 일치하지 않는 행은 포함하지 않는다.
'코딩 테스트 > 30 Days of Pandas' 카테고리의 다른 글
| [10일차] python&sql (0) | 2023.08.26 |
|---|---|
| [8일차] python&sql (0) | 2023.08.24 |
| [7일차] python&sql (0) | 2023.08.23 |
| [6일차] python&sql (0) | 2023.08.22 |
| [5일차] python&sql (0) | 2023.08.21 |