
이번 포스팅에서는 웹크롤링의 개념을 간단히 정리하고, 잡코리아의 데이터 분석가 채용공고로 실습을 진행했다. 먼저, 웹크롤링이란 무엇인지 살펴보자.
Web Crawling
웹 크롤링(Web Crawling)은 웹봇 또는 크롤러라고 불리는 자동화된 스크립트나 프로그램을 사용하여 월드 와이드 웹(WWW)에서 데이터를 체계적으로 검색하고 수집하는 행위를 의미한다. 즉, 웹 페이지에서 데이터를 수집하는 방법이다. 크롤링을 위해서는 인터넷 프로토콜 HTTP에 요청을 보내야 하는데, 방법과 요청 코드는 다음과 같다.
- Get
- URL에 Query 포함
- Query(데이터) 노출, 전송 가능 데이터 작음
- Post
- Body에 Query 포함
- Query(데이터) 비노출, 전송 가능 데이터 많음
- Client와 Server가 데이터를 주고 받은 결과 정보
- 2XX - Success
- 3XX - Redirect
- 4XX - Request Error
- 5XX - Server Error
정상적으로 요청에 성공하면, 2XX를 return하고, 실패하면 보통 4XX를 return 한다. 간단하게 개념을 정리했으니, 잡코리아에서 데이터 분석가 채용공고를 검색하고 결과를 확인해보자.

https://www.jobkorea.co.kr/Search/?stext=데이터 분석가
URL을 보면 다음과 같은 구성을 확인할 수 있다.
- https://www.jobkorea.co.kr/Search/는 잡코리아 사이트의 검색 페이지 URL의 기본 부분
- ?stext= 뒤에 오는 부분이 실제 검색어를 나타냄
- 데이터 분석가는 우리가 검색한 값으로, 실제는 공백 문자 인코딩으로 데이터%20분석가로 출력
따라서 주소 뒤 ?stext= 다음에 오는 부분이 사용자가 입력한 검색어를 URL 인코딩한 값임을 알 수 있다. 이를 통해 잡코리아에서 해당 검색어로 검색 요청을 진행함을 확인했다.
https://www.jobkorea.co.kr/Search/?stext=데이터 분석가&tabType=recruit&Page_No=2
사진의 왼쪽 위를 보면, 오늘을 기점으로 79건의 채용 공고가 등록되어있다. 스크롤을 내려서 다음 페이지로 가면, tabType과 Page number를 확인할 수 있다. 우리는 여기서 Page_No의 값을 조절하면 페이지가 넘어감을 확인했다. URL을 확인했으니, 이제 Python으로 채용공고를 가져와보자.
Code
import requests
import pandas as pd
from bs4 import BeautifulSoup
search = '데이터 분석가'
url = f'https://www.jobkorea.co.kr/Search/?stext={search}&tabType=recruit&Page_No=1'
response = requests.get(url)
dom = BeautifulSoup(response.text, "html.parser")
elements = dom.select("li.list-post")
elements
f-string을 활용하고, 데이터 분석가 공고의 1페이지를 요청했다. 하지만, 저렇게 요청하면 response는 200이지만 결과는 빈 리스트가 출력된다. 이유가 뭘까?
Python은 코딩으로 user-agent 정보를 설정해서 서버로 보내고, 해당 서버에서 이를 처리하면 결과를 반환한다. 이런 오류가 발생하는 경우, requests 과정에서 headers 매개변수를 추가해야한다.


크롬 브라우저에서 F12를 눌러서, 개발자 도구를 실행한다. 상단 탭 - Network - Fetch/XHR - 새로고침(F5) 순으로 실행하면, 해당 브라우저가 어떤 방식으로 요청값을 받는지 확인할 수 있다. 왼쪽의 Name을 누르고, headers - requests headers - User-Agent의 값을 dict 형태로 headers에 넣으면 문제를 해결할 수 있다. 그래도 안된다면, Referer를 추가하고, 또 다른 요소를 추가하는 방식으로 해결해야한다. 웹 서버마다 어뷰징을 체크하는 기준이 다르기 때문이다. 여기서는 User-Agent의 값만으로 정상적으로 요청을 받아올 수 있었다.
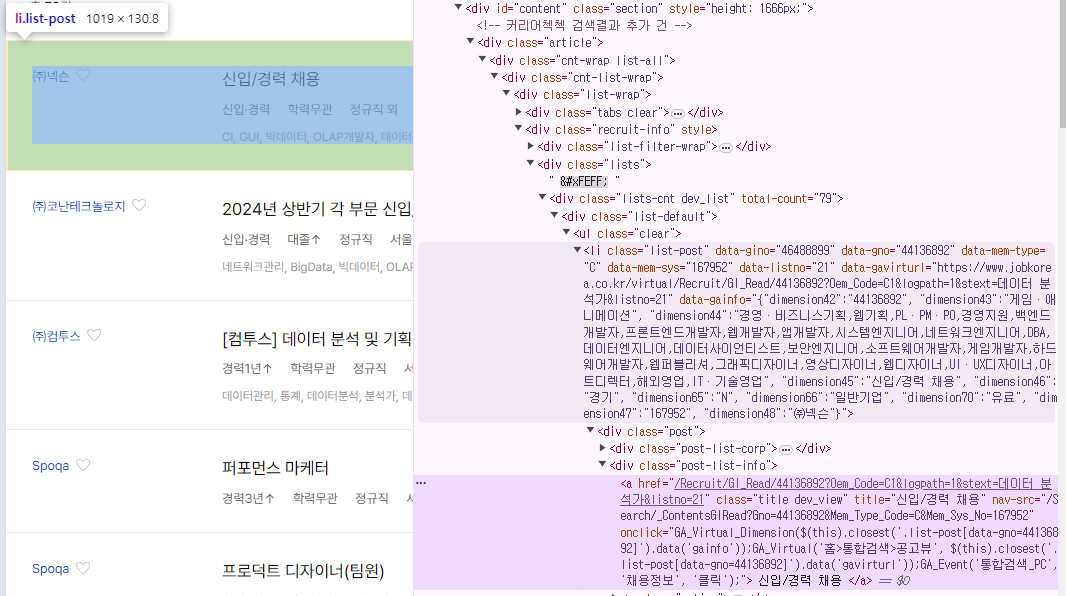

response에 성공했으면, 필요한 정보가 어떤 Tag에 있는지 찾아야한다. 우리가 필요한 정보는 회사명, 공고 제목, 채용 조건이다. 수많은 태그 중, li class list-post에 기업별 공고가 있음을 확인했다. 이 때, class의 개수가 여러 개 이기 때문에 select_one이 아닌 select 메서드를 사용해야한다.
태그를 자세히보고 우리가 필요한 정보를 가지고 있는 태그와 class명을 찾아야한다. 내가 찾은 정보는 아래와 같다.
- data-gainfo : 공고 제목, 산업, 회사명
- p.option : 연차, 학력, 근무지, 채용 유형
- div.post-list-info a : 채용 공고 링크
이제 필요한 정보만을 가져와서, DataFrame으로 묶어보자.
data = []
for tag in elements: # tags는 bs4.element.Tag 객체들의 리스트
gainfo = tag.get('data-gainfo')
link_tag = tag.select_one('div.post-list-info a')
p_tag = dom.find('p', class_ = 'option')
if gainfo :
gainfo_dict = eval(gainfo)
row = {
'title' : gainfo_dict.get('dimension45'),
'industry' : gainfo_dict.get('dimension43'),
'company' : gainfo_dict.get('dimension48'),
'link': link_tag.get('href') if link_tag else '',
'exp' : '',
'edu' : '',
'location':'',
'hiring_period' : ''
}
for span in p_tag.find_all('span'):
if 'exp' in span.get('class', []):
row['exp'] = span.text.strip()
elif 'edu' in span.get('class', []):
row['edu'] = span.text.strip()
elif 'loc' in span.get('class', []):
row['location'] = span.text.strip()
elif 'date' in span.get('class', []):
row['hiring_period'] = span.text.strip()
data.append(row)
df = pd.DataFrame(data)
df['link'] = df['link'].str.replace('virtual/','') # link 가상 경로 제거
df.head()
한 가지 주의해야할 점이 있다. div.post-list-info a 태그에서 가져온 링크는 가상 경로(Virtual path)를 나타내고 있다. 웹 서버에서는 실제 시스템의 경로와 다른 가상 경로를 매핑할 수 있다. 이렇게 하면 웹 사이트의 구조를 숨기고 보안을 강화할 수 있다. 실제 공고 링크와 맞추기 위해, link column에서 virtual/을 제거해야한다.

원하는 결과를 확인할 수 있다. 1페이지의 데이터를 가져왔으니, 이제 데이터 분석가 공고 전체를 가져오는 함수를 선언해보자.
사용자 정의 함수(잡코리아)
import pandas as pd
from bs4 import BeautifulSoup
import requests
import re
def job_korea(search, page_no):
data = []
for page in range(1, page_no+1):
url = f'https://www.jobkorea.co.kr/Search/?stext={search}&tabType=recruit&Page_No={page}'
response = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'})
dom = BeautifulSoup(response.text, "html.parser")
elements = dom.select("li.list-post")
for tag in elements:
gainfo = tag.get('data-gainfo')
link_tag = tag.select_one('div.post-list-info a')
p_tag = tag.select_one('p.option')
if gainfo:
gainfo_dict = eval(gainfo)
row = {
'title': gainfo_dict.get('dimension45'),
'industry': gainfo_dict.get('dimension43'),
'company': gainfo_dict.get('dimension48'),
'link': '',
'exp': '',
'edu': '',
'location': '',
'hiring_period': ''
}
if link_tag:
link = link_tag.get('href')
if re.match(r'^/Recruit', link):
row['link'] = 'https://www.jobkorea.co.kr' + link
else:
row['link'] = link
for child in p_tag.children:
if child.name == 'span':
if 'exp' in child.get('class', []):
row['exp'] = child.text.strip()
elif 'edu' in child.get('class', []):
row['edu'] = child.text.strip()
elif 'loc' in child.get('class', []):
row['location'] = child.text.strip()
elif 'date' in child.get('class', []):
row['hiring_period'] = child.text.strip()
data.append(row)
df = pd.DataFrame(data)
df['link'] = df['link'].str.replace('virtual/', '') # 가상 경로 제거
return df
df = job_korea('데이터 분석가', 5)
df.head()

페이지를 합치면서 새로운 문제점을 몇 가지 발견했다. 마지막 페이지의 링크는 잡코리아의 링크가 아닌, "게임잡" 이라는 게임 구직 사이트와 연동되어 있다. 또한, 잡코리아의 모든 링크가 Https 프로토콜이 아닌 /Recruit로 시작하고 있다. 정규식으로 조건을 제시하고, 문자열을 결합해서 해결할 수 있었다.
아직 실력이 많이 부족하지만, 지금보다 더 부족하던 시절 웹크롤링을 시도하며 다른분들의 코드를 많이 참고했었다. 나보다 더 뛰어나신 분들도 훨씬 많고, 더 고도화된 방법으로 크롤링을 하시는 분들도 분명히 계시지만 누군가에겐 나의 코드가 도움이 되기를 바라며 포스팅을 마무리하려고한다. 또한, 학습의 목적이라도 과도한 크롤링으로 서버에 과부하를 주는 경우 업무 방해 등으로 법적인 제재를 받을 수 있으니, 주의하기 바란다. 차후에는 다른 채용 사이트도 분석해서, 최종적으로 데이터 분석가를 시장에서 몇명이나 뽑는지, 어떤 역량을 요구하는지 시각화하는 것을 목표로 해야겠다.
'Aivle > Project' 카테고리의 다른 글
| [에이블스쿨] 구글 플레이 스토어 리뷰 분석 (0) | 2024.05.19 |
|---|---|
| [에이블스쿨] GCP, Naver Cloud, 형태소 분석기 바른 (1) | 2024.04.20 |
| [에이블스쿨] RFM, Retention (0) | 2024.03.12 |
| [에이블스쿨] Python에서 WorkBench 연결 (0) | 2024.03.10 |
| [에이블스쿨] E-커머스 장기 미구매 고객 탐색 (2) | 2024.03.09 |